Año 9, Número 3. Mayo - Agosto, 2022. 
Reconocimiento de objetos usando conjuntos pequeños de entrenamiento
Object recognition using small training sets
Universidad de Guanajuato
Por: Felipe Trujillo-Romero / Ver en pantalla completa
Resumen
En este trabajo se presenta la implementación de un sistema de reconocimiento de objetos, el cual utiliza solo cuatro vistas de cada objeto para entrenar a la red neuronal de Mapas Autoorganizados. Los objetos utilizados son los de la base de datos COIL-20. La extracción de características se realiza a partir del algoritmo de histogramas de gradientes orientados y sirven de entrada para la red neuronal. Para validar la robustez del sistema implementado se utilizó el método de validación cruzada. Con este método se mostró que el sistema tiene un porcentaje de reconocimiento del 85 %. Además, se encontró que el sistema de reconocimiento es estable a cambios en la posición de los objetos.
Palabras clave: redes neuronales; mapas autoorganizados; histograma de gradientes orientados; reconocimiento de objetos, validación cruzada.
Abstract
This paper presents the implementation of an object recognition system which uses only four views of each object to train the neural network of Self-Organizing Maps. The objects used are those of the COIL-20 Database. The feature extraction is carried out with the Oriented Gradient Histograms algorithm, and they are used as input for the neural network. To validate the robustness of the implemented system, the cross-validation method was used. With this method, it was shown that the system has a recognition percentage of 85%. Besides, it was found that the recognition system is stable to changes in the position of objects.
Keywords: neural networks; self-organizing maps; histogram of oriented gradients; object recognition, cross validation.
Introducción
De todas las distintas tareas que se realizan mediante el uso de algoritmos de visión por computadora, una de las más difíciles es la de poder analizar una escena y reconocer los objetos que se encuentran presentes en ella. Este proceso es el que se denomina en la literatura como reconocimiento de objetos y en términos generales se define como un problema de clasificación en el que el objetivo es etiquetar a un objeto como parte de una categoría específica. El reconocimiento se puede realizar sobre múltiples objetos en una escena o sobre objetos ya aislados. En este caso se enfocará en el reconocimiento de objetos donde las imágenes de prueba muestran un único objeto a reconocer.
Para el reconocimiento e identificación de objetos se han utilizado varias técnicas. Entre ellas se tiene la de detección de objetos, en las cuales se mencionan la coincidencia de plantillas, el reconocimiento basado en la forma, y el reconocimiento basado en el color/textura. La coincidencia de plantillas es un método que se basa en tener una imagen como plantilla y tratar de encontrar apariciones de esa plantilla en una imagen. Este método se utiliza con frecuencia con texto e imágenes sin color.
El reconocimiento basado en formas consiste en detectar objetos utilizando sus formas. Los bordes de un objeto pueden permitir la mayor parte del tiempo hacer coincidir el objeto. Esta técnica se puede utilizar tanto para imágenes en color como para aquellas en escala de grises. El color, en este caso, no se considera un criterio de detección.
Sin embargo, el reconocimiento basado en colores consiste en utilizar el basado en formas y agregarle el criterio de color. En esta técnica, se comienza a tener en cuenta los colores. Estos se convierten en información adicional que puede ayudar aún más a identificar objetos que tienen histogramas de color particulares.
Teniendo en cuenta el hecho de que los objetos dentro de una escena pueden tener diferentes colores y tonos, además de poseer diferentes texturas, el uso de la coincidencia de plantillas y el reconocimiento basado en colores sería ineficaz. Por lo tanto, lo ideal es optar con un método basado en formas.
Dentro de este tipo de métodos basados en formas, uno de los más ampliamente utilizado es el Histograma de gradientes orientados1(HOG). Esta técnica de HOG se utiliza para extraer características de objetos después de un cambio en la intensidad.
Por lo tanto, siguiendo la distribución de esos gradientes de intensidad, los bordes de los objetos se resaltan para permitir extraer las características y discernir las formas con mayor claridad. Después de obtener su forma, el objeto se clasifica mediante una técnica de aprendizaje automático, en este caso se utilizó el método de las redes de Kohonen (también conocido como mapas autoorganizativos)2.
Con la finalidad de validar el algoritmo propuesto en este trabajo se utilizaron las imágenes de los objetos contenidos en la base de datos COIL-203. Una de las ventajas de utilizarla es que al ser una base de imágenes conocida se pudiera tener un referente en cuanto al desempeño del sistema propuesto.
Además, es una de las bases de objetos de gran uso, como se puede ver en diversos trabajos de investigación.
Por ejemplo, Model y Shamir4 han realizado una comparativa entre varias bases de datos, pero resaltan el hecho de que la COIL-20 tiene objetos variados y es útil para tareas de reconocimiento.
Por su parte, Deng et. al.5 implementaron un sistema de reconocimiento de objetos basado en el modelado biológico de la visión humana usando la base de objetos de COIL-20.
Otro caso es el de la detección y el reconocimiento de dígitos escritos a mano (MNIST6), así como de los objetos presentes en la COIL-20 se realizó mediante el uso, principalmente, de la distancia de Hausdorff, por Bhadane et. al.7 y por Kumar et. al.8 respectivamente.
Mientras que Ou et. al.9 han usado un nuevo esquema llamado perceptrón bidimensional, también para el reconocimiento de dígitos presentes en la base MNIST y objetos de la COIL-20. Por su parte, Fang y Lin10 usaron un esquema multidimensional para el reconocimiento de MNIST y de COIL-20 principalmente; además de usar SOM como parte del sistema de reconocimiento.
Por lo que se refiere a Huang y Zhou11, implementaron un mecanismo de reconocimiento con una red neuronal al que llamaron red de cápsulas con atención dual (DA-CapsNet0) para reconocer objetos presentes en diferentes bases, entre ellas la MNIST y la COIL-20.
Además de los métodos de reconocimiento de objetos de la COIL-20 que se han mencionado en párrafos anteriores, también se han usado otros, como por ejemplo GIST y máquina de vector de soporte (SVM), implementado por Meera y Mohan12. También se han usado los momentos radiales de Hahn, tanto en 2D como en 3D, basados en la representación polar de un objeto mediante polinomios de Hahn13. El descriptor basado en la transformada de Radon-Fourier ha sido implementado por Yang et. al.14 para reconocer la COIL-20. Mohan et. al.15 han implementado un sistema que utiliza momentos gaussianos de Hermite y SVM para reconocer objetos presentes tanto en la COIL-20 como en la COIL-100.
Implementaciones de redes neuronales de profundidad16 y redes convolucionales17, así como redes neuronales tradicionales18 también se han empleado para reconocimiento de estas bases de objetos.
Para finalizar con esta revisión, se mencionan los trabajos de Prabhu et. al.19, Qaraei et. al.20 y Kim et. al.21, quienes han empleado otro tipo de métodos para llevar a cabo la tarea de reconocimiento de objetos orientado a bases de datos como la COIL-20. Por ejemplo, Prabhu et. al.19 han implementado redes neuronales pulsantes. Mientras que Qaraei et. al.20 usaron un esquema de fusión de Análisis de componentes principales (PCA) con redes neuronales convolucionales como sistema de reconocimiento de objetos. Finalmente, Kim et. al.21 emplearon un sistema basado en inteligencia de enjambres para la realización de generación de grupos (clusters) de las imágenes que componen cada uno de los objetos presentes en la COil-20, entre otras bases.
Como se puede ver, los trabajos mencionados son solo algunos métodos que se han empleado para la detección y el reconocimiento de los objetos que se incluyen en diversas bases de datos, principalmente en la COIL-20.
Objetivo
Objetivo principal
Implementar un sistema que sea capaz de reconocer una serie de objetos a partir del aprendizaje de un conjunto reducido de vistas diferentes de cada uno de estos objetos.
Objetivos secundarios
- Utilizar una red neuronal con aprendizaje no supervisado, como lo son los mapas autoorganizados. Dicha red neuronal será el elemento principal del sistema de reconocimiento de objetos.
- Usar solo cuatro vistas diferentes de cada uno de los objetos, que proporcionen la mayor cantidad de características de este, con la finalidad de que el sistema de reconocimiento las aprenda y pueda reconocerlos desde cualquier punto de vista.
- Validar la estabilidad del sistema mediante el método de referencias cruzadas, usando diferentes configuraciones de entrenamiento y prueba, pero con una selección aleatoria de elementos.
Planteamiento del problema
En este trabajo se aborda el problema de reconocimiento de objetos y se propone un esquema en el que se utiliza aprendizaje no supervisado sobre un conjunto mínimo de imágenes de los objetos a aprender, para su posterior reconocimiento.
En específico, lo que se propone es la extracción y generación de clústeres a partir de la distribución generada por el descriptor de los objetos utilizado. Una vez generados, los clústeres son etiquetados como pertenecientes a una misma clase o tipo de objeto u objetos si fuera el caso.
Se propone implementar un sistema de reconocimiento de objetos utilizando para ello una red neuronal autoasociativa como lo es la red de Kohonen. La entrada para esta red neuronal será el vector de características morfológicas basado en el histograma de gradientes orientados. Este será el descriptor de los objetos que se encuentran en la base de imágenes que se va a utilizar para entrenar, probar y validar el algoritmo a implementar.
La base de datos a utilizar será la generada por la Universidad de Columbia y que se denomina COIL-20 (Columbia University Image Library - 20). Esta base posee 72 imágenes de cada uno de los 20 objetos diferentes que incluye.
Ahora bien, para evaluar y validar el algoritmo de reconocimiento de objetos a implementar, se realizarán tres tipos de experimentos.
El primero será usando 18 imágenes de cada objeto para entrenar la red. Estas imágenes estarán al mismo ángulo de separación unas de otras. Posteriormente, una vez entrenada la red, se podrá obtener el porcentaje de reconocimiento del sistema después de reconocer las 54 imágenes por objeto restantes. Esta tasa de reconocimiento servirá para establecer una referencia en este parámetro, pues lo que interesa es que el sistema empleado sea capaz de aprender con menos imágenes.
El segundo experimento será el objetivo principal de este trabajo. Es decir, se entrenará a la red de Kohonen con solo 4 imágenes por objeto, espaciadas 90° entre ellas. Esta prueba permitirá determinar si el planteamiento inicial es correcto o si sería necesario hacer ajustes a algún elemento del sistema de reconocimiento.
Finalmente, se realizarán pruebas de estabilidad y robustez al sistema mediante la utilización del método de referencias cruzadas. Aquí se tomarán diferentes conjuntos de imágenes espaciadas usando diferentes rangos angulares tanto para el entrenamiento como para la evaluación. Esto con la finalidad de determinar si el sistema empleado es consistente y por consecuencia robusto.
Método de trabajo
Base de objetos COIL-20
La base de datos de imágenes COIL-203 consiste en una colección de imágenes de 20 objetos diferentes, los cuales se muestran en la Figura 1. Las características de esta base son las siguientes:
- De cada objeto se tiene una toma cada 5° hasta completar una perspectiva completa de 360°, con esto se tiene un total de 72 imágenes para cada uno de los objetos en la base, formando un total de 1,440 imágenes.
- Estas imágenes se encuentran en escala de grises.
- El tamaño de cada imagen es de 128 x 128 pixeles.
- Los objetos tienen características similares (forma, color, entre otros).
De cada uno de estos 20 objetos se eligieron 4 vistas diferentes de tal forma que diera una apreciación del objeto. Estas vistas se encuentran a 0°, 90°, 180° y 270°. En la Figura 2 se muestran las cuatro vistas elegidas para uno de los objetos de la COIL-20.
La principal razón de solo utilizar 4 imágenes para el entrenamiento fue debido a la búsqueda de un conjunto mínimo de imágenes de un objeto que nos permita extraer las características relevantes de los objetos. Lo ideal es tener un sistema que sea capaz de reconocer un objeto con solo 1 vista del objeto. Sin embargo, la mayoría de las veces no es tan simple determinar, de manera automática, la vista que nos pueda proporcionar la mayor cantidad de información del objeto. Por esa razón, se optó por tener una imagen del objeto cada 90° empezando en 0°.

Figura 1. Base de objetos COIL-203 https://www.cs.columbia.edu/CAVE/software/softlib/coil-20.php
Cabe mencionar que se puede tomar cualquier imagen inicial y a partir de ella considerar las siguientes imágenes cada 90°. Por ejemplo, si la imagen inicial fuera la de 25°, las otras tres restantes serían las que se encuentran a 115°, 205° y 295°.

Figura 2. Vistas usadas para entrenar3: (1) 0°, (2) 90°, (3) 180°, y (4) 270°. https://www.cs.columbia.edu/CAVE/software/softlib/coil-20.php
Para denominar a las clases a las que pertenecen los objetos de la base COIL-20, se utilizó el número de objeto de acuerdo a como están ordenados en dicha base, así que las imágenes del objeto colocado en la primera posición dentro de la base de objetos pertenecerán a la clase número 1. De esta manera, las imágenes de los objetos mostrados en la Figura 1 les corresponderá la clase según el número que poseen. Por lo cual, a partir de ahora, al tratarse de una clase en particular, se hará referencia al número asociado al objeto.
Descriptor de imágenes
En este trabajo se decidió utilizar un descriptor que atendiera principalmente a las características morfológicas de los objetos, pero que a su vez fuese sencillo de implementar y utilizable en el contexto de una red neuronal sin necesidad de realizar muchos ajustes. Por esa razón se usó el histograma de gradientes1 (HOG) como descriptor.
Este descriptor está basado en la idea de que la apariencia y forma de una región específica en un objeto pueden ser caracterizadas por la distribución de intensidad o dirección de los gradientes en dicha región, sin que sea necesario saber la posición exacta de dichos gradientes. Para crear un descriptor basado en HOG el proceso que se sigue es el siguiente:
1. La imagen se divide en celdas del mismo tamaño (
2. Para cada celda se obtiene la distribución de intensidades o direcciones de los gradientes medidos sobre cada pixel en la celda. Se calcula, tanto en la dirección horizontal como en la dirección vertical, el operador de Sobel para la obtención del gradiente, el cual es el que se muestra en las ecuaciones 1 y 2.
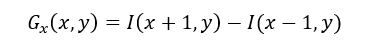 (1)
(1)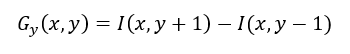 (2)
(2)Se obtiene de esta manera la relación para la magnitud del gradiente, el cual se utiliza como una aproximación del gradiente de la imagen de entrada. Esta aproximación del gradiente se calcula de acuerdo con la ecuación 3.
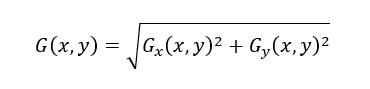 (3)
(3)3. Así mismo, se puede calcular el ángulo que indica la dirección del gradiente obtenido, mediante la ecuación 4.
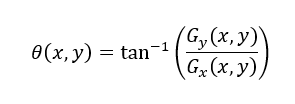 (4)
(4)4. El siguiente paso es crear los histogramas de cada celda. Este histograma se crea a partir de la dirección de cada pixel dentro de la celda, el cual emite un voto ponderado para un canal de histograma basado en la orientación, según los valores encontrados en el cálculo del gradiente. Los contenedores para este histograma se distribuyen uniformemente en un rango de 0° a 180° usando 9 canales para almacenar los valores obtenidos.
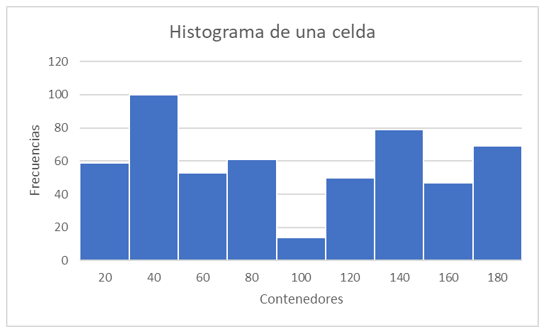
Figura 3. Ejemplo de un histograma de 9 contenedores de una celda de la imagen. Fuente: elaboración propia
En la Figura 3 se puede observar un ejemplo de este histograma generado en una celda determinada de la imagen. Aquí se observa que cada contenedor está centrado en 20°. Esto es debido a que se tiene un rango de 180° y se usan 9 contenedores, así que las frecuencias de las orientaciones por las que vota cada pixel se agrupan usando esta distribución.
5. Posteriormente estas distribuciones son normalizadas dentro de bloques (blocks) de mayor tamaño que agrupan varias celdas. Esta normalización se realiza mediante el uso de la relación de la L2-norma, que se puede observar en la ecuación 5.
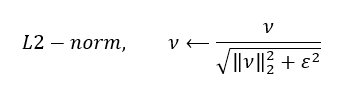 (5)
(5) Donde ν es el vector no normalizado que contiene todos los histogramas en un bloque dado, ‖ν‖k es su k-norma para k = 2 y ε es una constante pequeña.
6. Finalmente, las distribuciones ya normalizadas se combinan formando un descriptor que consta de 144 valores. Estos valores se obtienen a partir de las 16 celdas totales para cada imagen y de cada celda se obtiene un histograma de 9 contenedores, por lo que el producto de celdas totales por contenedores por celda es igual a 144.
Para la obtención de los descriptores de las imágenes se utilizó la implementación de HOG que contiene la librería OpenCV22. La configuración que se utilizó para obtener cada descriptor es: tamaño de celda de 32 x 32 pixeles, un tamaño de ventana de 64 x 64pixeles y un corrimiento de 64 pixeles.
La selección del tamaño de celda de 32 X32 pixeles fue producto de la realización de diferentes pruebas con varios tamaños. Mediante esta experimentación se determinó que la dimensión de celda que tenía un desempeño similar al sugerido en el artículo de Dalal y Triggs1 era la celda de 32 x 32. Este tamaño de celda era más rápido.
Además, considerando que este descriptor1 se creó originalmente para detectar peatones, en el cual se usó un tamaño de imagen de 128 x 64. Sin embargo, en el caso de los objetos de la COIL-20 se usan imágenes de 128 x 128. Fue la celda de 32 x 32 la que se adaptó mejor tanto al tamaño de imágenes como a los objetos que se quería que el sistema aprendiera y reconociera posteriormente. En la Figura 4(a) se observa una imagen del objeto número 1 cuya orientación es 0°. A esta imagen de entrada se divide en 4 bloques (ver la Figura 4(b)), donde, como se puede apreciar en la Figura 4(c), cada bloque a su vez contiene exactamente cuatro celdas. De cada una de estas celdas se extrae la distribución de dirección de los gradientes de la imagen de bordes del objeto, esto se puede ver en la Figura 4(d). Dicha distribución se almacena usando 9 contenedores igualmente espaciados, obteniéndose la imagen resultante de estos histogramas que se puede observar en la Figura 4(e).
Al final se toman los valores normalizados de distribución de cada celda y se obtienen los 144 valores de cada vector de características.
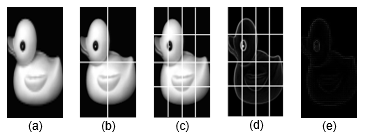
Figura 4. (a) imagen original, (b) 4 bloques, (c) 4 celdas por bloque, (d) imagen de gradiente, y (e) descriptor HOG obtenido. Fuente: elaboración propia
Mapa autoorganizado
Los mapas autoorganizados (SOM, por sus siglas en inglés) son un modelo de red neuronal artificial que es entrenada por aprendizaje no supervisado y obtiene una representación discreta del espacio de entrenamiento. Uno de los modelos más populares de SOM fue propuesto por el profesor Teuvo Kohonen, por lo que también se le conoce como Red de Kohonen2.
La idea principal de este algoritmo es que, dado un conjunto A de vectores de entrada, también conocido como espacio de la red, la red de Kohonen tiene como objetivo generar una partición del conjunto A en m regiones disjuntas, a1,a2,…,am. (Ver las ecuaciones 6)
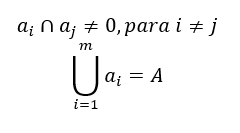 (6)
(6)El objetivo es que la red de Kohonen “cubra” al conjunto A, de tal forma que para cada vector de entrada se active una y solo una neurona. Es decir, si el conjunto A se divide en m regiones, entonces la red de Kohonen debe contar con al menos m neuronas y cada neurona se especializará en una y solo una región.
Dicho de otra manera: la red de Kohonen realiza una clasificación de los vectores de entrada y estas clases definen una representación de la estructura del espacio de la red. La malla que resulta de la red de Kohonen sobre el conjunto A se denomina mapa del espacio.
Por lo tanto, se puede ver a las redes de Kohonen como arreglos de neuronas con topologías de diferentes dimensiones o n-dimensional, en donde la estructura de la red está formada por m neuronas y cada neurona recibe un vector de entrada X con n componentes. Cada neurona j, para j = 1,…,m, tendrá asociado un vector de pesos 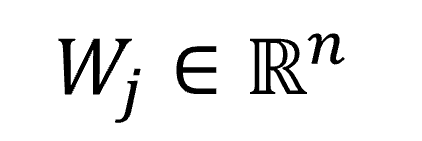 denominado centro de gravedad y servirá para obtener la salida correspondiente de la red. Entonces, cuando se presenta un vector de entrada a la red, a la neurona que proporcione la salida con valor mínimo se le denomina neurona ganadora y estará asociada a la clase que pertenece el vector de entrada.
denominado centro de gravedad y servirá para obtener la salida correspondiente de la red. Entonces, cuando se presenta un vector de entrada a la red, a la neurona que proporcione la salida con valor mínimo se le denomina neurona ganadora y estará asociada a la clase que pertenece el vector de entrada.
Para encontrar la región a la que pertenece la neurona ganadora y por consiguiente el vector de entrada X, se calcula la distancia euclidiana entreX y cada uno de los vectores de pesos Wj, para j=1,…,m.
La actualización de los pesos se realiza a partir de la vecindad de radior de la red que está asociada a la j-ésima neurona, y se define como el conjunto de neuronas localizadas hasta r posiciones de la neurona j. En el proceso de entrenamiento se define la fuerza de enlace entre dos neuronas j y k, como una función φ(j,k,r) definida en la ecuación 7.
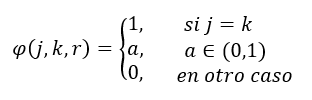 (7)
(7)Por lo tanto, la actualización de los pesos Wj, para j, k =1,…,m, está dada por la ecuación 8.
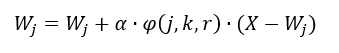 (8)
(8)Donde α es el coeficiente de aprendizaje y por lo general α ∈(0,1). El coeficiente de aprendizaje tiene como objetivo controlar la magnitud de la actualización de los pesos.
Con el conjunto de vectores de entrenamiento, el SOM construye un mapa y con el conjunto de prueba se realiza la clasificación de una entrada determinada. El algoritmo recibe el conjunto de vectores de entradas, el coeficiente de aprendizaje y el número de neuronas en la red.
En el presente trabajo, la estructura de la red neuronal de SOM que se utilizó estaba formada por una estructura rectangular de 5 x 5 celdas, lo que es igual a 25 neuronas, razón de aprendizaje de 0.2 y 600 épocas de entrenamiento.
Los parámetros utilizados para la configuración fueron elegidos mediante una serie de entrenamientos para determinar cuáles eran los valores más adecuados para cada uno de ellos.
En la Figura 5, se puede observar el histograma de épocas y las frecuencias para cada uno de los valores obtenidos. Este histograma se obtuvo a partir de 1000 entrenamientos realizados. Para cada uno de estos entrenamientos se recuperó la cantidad máxima de épocas en las cuales ya no existía una variación en el ajuste de los pesos de la red. Se puede apreciar que el valor máximo de épocas es de 600, razón por la cual se determinó este valor como el límite superior para este parámetro.
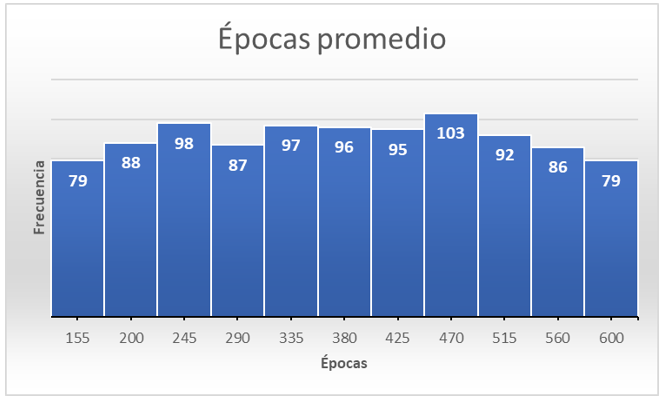
Figura 5. Frecuencias de épocas después de 1000 entrenamientos de la red neuronal. Fuente: elaboración propia
Por otra parte, se tiene el valor de la razón de aprendizaje α. Para determinar el valor de alfa se realizó una serie de entrenamientos para encontrar cuál era el valor que daba una mejor tasa de reconocimiento. De igual manera que para determinar el valor de las épocas, se realizaron un conjunto de 1000 entrenamientos a partir de los cuales se eligió el valor de 0.2 para alfa, dado que este dio un mayor porcentaje de reconocimiento (ver la Figura 6).
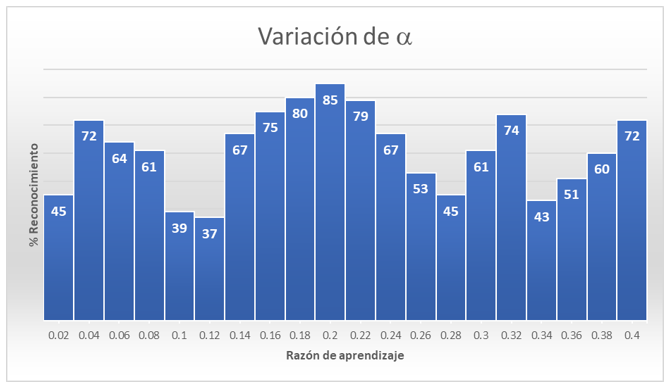
Figura 6. Tasa de reconocimiento para diferentes valores de α. Fuente: elaboración propia
Finalmente se tiene el valor de neuronas para el mapa de Kohonen. Cabe mencionar que este fue el más sencillo de determinar debido a que como eran 20 objetos los que se quería que la red neuronal aprendiera, y como la red requiere por lo menos una neurona por cada clase, es decir, por objeto, entonces solo se requerían 20 neuronas. Sin embargo, tanto la literatura como la experiencia propia en el uso de este tipo de sistemas indica que se deben agregar más neuronas que las clases a aprender. Por esa razón, se optó por el valor de 25 neuronas para generar un mapa cuadrado de 5 x 5 neuronas.
Sistema de reconocimiento
El diagrama que se muestra en la Figura 7 es el que se lleva a cabo para la realización del sistema de reconocimiento presentado en este trabajo. En la Figura 7, se pueden apreciar las dos fases del sistema: aprendizaje y reconocimiento. Durante la fase de aprendizaje se realiza el entrenamiento de la red neuronal, donde se ajustan los pesos de las conexiones de las neuronas. Aquí se generan las asociaciones de los datos que se presentan al SOM. Estas asociaciones son las que el sistema requiere para poder reconocer un nuevo vector de entrada; en el esquema de la Figura 7 esto se representa mediante la parte de almacenamiento de la base de conocimiento.
Siguiendo este esquema (Figura 7), la fase de reconocimiento se inicia con la obtención de los vectores a partir de la extracción de características. Esta extracción de características se realiza mediante el uso de HOG en las imágenes no usadas para entrenar el sistema. Este vector es evaluado por la red neuronal para generar la etiqueta del objeto reconocido.
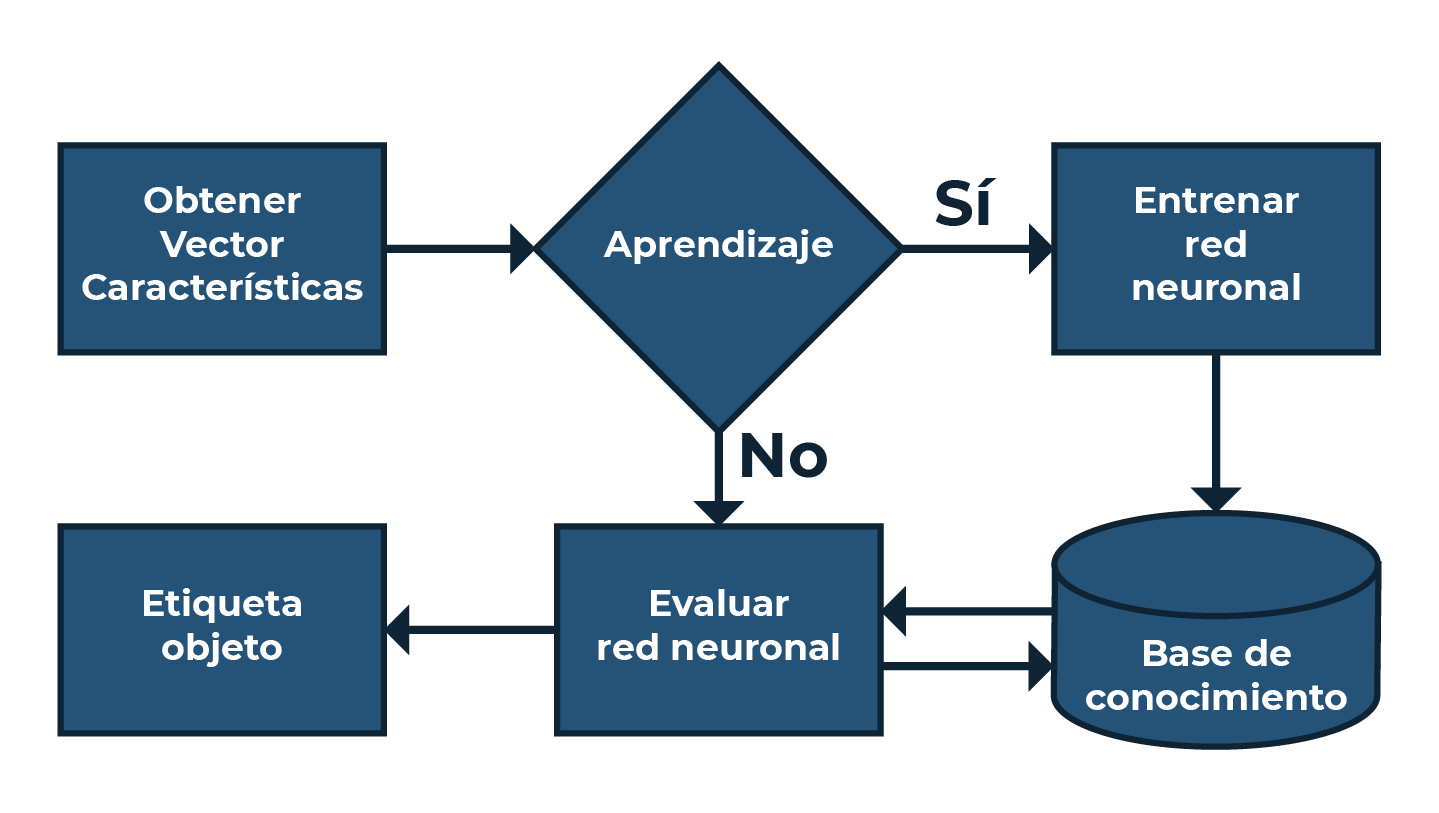
Figura 7. Diagrama de flujo del sistema de reconocimiento. Fuente: elaboración propia
Evaluación
Con el fin de obtener resultados preliminares que permitan al investigador tener una vista del comportamiento que tendrá la red con un conjunto más pequeño de datos de entrenamiento, se realizó una fase de prueba para evaluar el desempeño del sistema de reconocimiento.
Para llevar a cabo esta prueba se tomaron 18 imágenes por objeto para el entrenamiento con una distancia de separación de 20° entre ellas. Esta distancia se estableció debido a la relación de 360° que existen para las imágenes de un objeto y el número de imágenes a utilizar en el entrenamiento. Además, que se busca que sean de diferentes puntos de vista para tener una mejor caracterización del objeto.
Una vez entrenado el sistema se procedió a la etapa de reconocimiento. En esta etapa fueron usadas las 54 imágenes restantes, que se reservaron para realizar la evaluación. Es importante recordar que cada clase se compone de 72 imágenes, de ahí que, si se usaron 18 de ellas para entrenar el sistema, la diferencia con el total es de 54.
A partir de la evaluación realizada a la red neuronal implementada se obtuvieron los resultados que se muestran en la Tabla 1, de la cual se pueden resaltar dos cosas principalmente. La primera es que se puede observar que existen varios objetos cuyas características son muy similares. Lo anterior se deduce del hecho de que se activan las mismas neuronas. Por ejemplo, en los objetos 3, 6 y 19, en los cuales son las neuronas 9, 15, 24 y 25 las que se activan con los vectores de características de dichos objetos. Cabe mencionar que este es un comportamiento deseado. Dicho comportamiento sería similar a lo que un ser humano sería capaz de determinar que los tres objetos (3, 6 y 19) pertenecen a los 3 carros de juguete y colocarlos en la misma clasificación. Por esta razón, el resultado obtenido por la red neuronal al asociar las imágenes que observa de diferentes objetos a una misma clase debido a que presentan similitudes morfológicas muy grandes entre ellos.
Algo similar sucede con los vectores provenientes de los objetos 5 y 9. Estos objetos pertenecen a dos cajas y de igual manera presentan características morfológicas que hacen ver a dichos objetos muy idénticos. Para estos objetos las neuronas que se activan son la 3, 6, 10 y 20.
Es importante resaltar que, en los dos casos anteriormente mencionados, las respectivas neuronas responden solo a descriptores de dichos objetos. Esto significa que al momento de que exista una posible confusión del vector de entrada que se está evaluando, dicha confusión siempre está relacionada con los objetos de características similares.
Dado que los objetos 3, 6 y 19 y los objetos 5 y 9 son reconocidos por el mismo grupo de neuronas respectivamente, entonces se pueden colocar en una sola clase cada uno de estos grupos de objetos.
Como segundo punto relevante, se observa que el objeto número 18 no es detectado por el sistema de reconocimiento. Y como se puede observar en la Tabla 1, de hecho, ninguna neurona se activa al vector de las características extraídas de las imágenes de este objeto. Por lo cual, el porcentaje de detección obtenido es del 0 %.
Tabla 1. Matriz de confusión para evaluación del sistema implementado. Fuente: elaboración propia
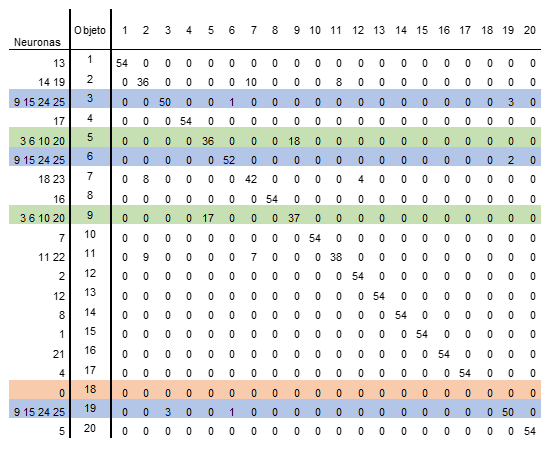
Con los resultados obtenidos se puede determinar que el porcentaje de detección del sistema es del 86.57 %. Finalmente, se puede verificar que el SOM implementado es robusto, ya que es capaz de detectar objetos que son parecidos y agruparlos dentro de una misma clase; aunque desafortunadamente hubo una clase que no logró detectar.
Resultados
Reconocimiento usando conjuntos pequeños de entrenamiento
Una vez que se tiene el sistema de reconocimiento evaluado y por consecuencia tener una referencia, es momento de entrenar la red neuronal, pero ahora con solo cuatro imágenes de cada uno de los objetos.
Es importante recordar que estas imágenes usadas para entrenar tienen una separación entre ellas para un mismo objeto de 90°, comenzando en 0° (véase la Figura 2).
Como ya se ha comentado, el objetivo es probar el sistema de reconocimiento usando solo un conjunto pequeño de imágenes por objeto. En este caso dicho conjunto pequeño estará formado por solo cuatro imágenes por objeto, que servirán para entrenar a la red neuronal, mientras que las otras 68 se dejarán para realizar la validación del aprendizaje.
Por lo que se entrena la red con 80 muestras totales para comparar el comportamiento que tiene respecto al entrenamiento previo usando 360 imágenes. La red neuronal usada en ambos experimentos es la que se menciona en la sección Mapa autoorganizado. Ya realizado el entrenamiento, se evalúan las imágenes restantes y en este caso se obtiene el resultado que se muestra en la Figura 8.
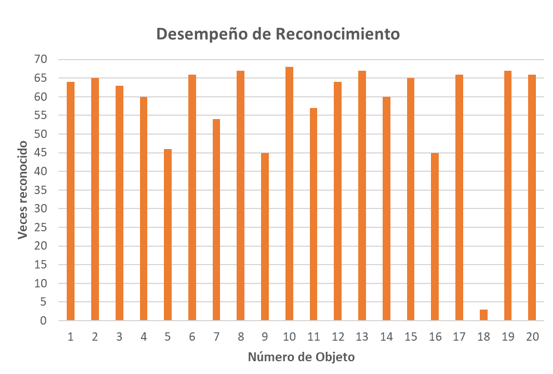
Figura 8. Desempeño del sistema implementado con solo cuatro imágenes por objeto. Fuente: elaboración propia
En la Figura 8, es posible observar la manera como se comporta el sistema de reconocimiento al ser entrenado con un conjunto pequeño de imágenes de cada objeto. Se puede ver en la Figura 8, que el desempeño realizado es muy similar al obtenido en la etapa de evaluación presentada en la sección titulada Evaluación.
Los puntos que se pueden resaltar de estos resultados son los a continuación se comentan:
- Se ve que sí fue posible que el objeto 18 sea reconocido, aunque muy pocas veces.
- Existen 10 clases u objetos que se reconocen al 100 %.
- De igual manera que, en el sistema previo, los objetos con características similares son asociados por las mismas neuronas.
- El porcentaje de reconocimiento obtenido fue de 85.14 %.
De manera general, se observa que el porcentaje de reconocimiento es tan solo 1.43 % menor al que se tuvo con el entrenamiento usando 18 imágenes por objeto, por esto puede decirse que presenta un buen desempeño respecto a un sistema que requiere más imágenes para entrenarse.
Estabilidad del sistema
Finalmente, y con el propósito de evaluar tanto la estabilidad como la robustez del sistema, se propusieron diferentes configuraciones de entrenamiento/pruebas.
Estas pruebas se realizaron con la misma base de datos, pero haciendo uso de una selección aleatoria tanto de la cantidad de imágenes como del ángulo de estas. Para esta tarea se utilizó la técnica que se conoce como validación cruzada.
El objetivo que tiene el uso de la validación cruzada es reforzar los resultados obtenidos mediante un análisis estadístico, lo cual permite darles un cierto grado de generalidad. Además, evita el obtener una buena tasa de reconocimiento solamente por aleatoriedad en la selección de los datos de entrenamiento y validación.
Por lo tanto, la validación cruzada consiste en iterar un conjunto de datos que previamente se ha dividido en un grupo de entrenamiento y otro de validación. Sin embargo, para disminuir la variación en el resultado obtenido se debe de iterar sobre distintos grupos. Posteriormente, los resultados se combinan para obtener la estimación del rendimiento del sistema.
Por esa razón, se utilizaron dos esquemas de entrenamiento y pruebas. Cada uno de esos esquemas se realizó de la forma siguiente:
Esquema 1
Se crearon 6 grupos, compuesto cada uno por 12 imágenes deferentes de cada objeto. Los grupos se organizaron de acuerdo a las distancias angulares entre imágenes de la siguiente manera:
- Grupo 1, imágenes entre 0° y 55°.
- Grupo 2, imágenes entre 60° y 115°.
- Grupo 3, imágenes entre 120° y 175°.
- Grupo 4, imágenes entre 180° y 235°.
- Grupo 5, imágenes entre 240° y 295°.
- Grupo 6, imágenes entre 300° y 355°.
A partir de estos grupos se realizaron 5 niveles de pruebas, cada una de ellas para considerar diferente número de imágenes tanto de entrenamiento como de prueba. Entonces, en este esquema 1, se formaron los siguientes grupos tomando de forma aleatoria la cantidad de imágenes que se indica a continuación:
- 2 imágenes de cada grupo para entrenamiento y 6 imágenes para prueba.
- 3 imágenes de cada grupo para entrenamiento y 6 imágenes para prueba.
- 4 imágenes de cada grupo para entrenamiento y 6 imágenes para prueba.
- 5 imágenes de cada grupo para entrenamiento y 6 imágenes para prueba.
- 6 imágenes de cada grupo para entrenamiento y 6 imágenes para prueba.
Resumiendo: en el primer esquema se tomaron respectivamente, y de forma aleatoria 12, 18, 24, 30 y 36 imágenes para entrenamiento y en cada caso 36 imágenes aleatorias y diferentes para pruebas de validación.
Esquema 2
En este esquema se crearon solo 4 grupos, cada uno de ellos compuesto por 18 imágenes por objeto. De manera similar al esquema 1, los grupos se organizaron de acuerdo con las distancias angulares entre imágenes de la siguiente manera:
- Grupo 1, imágenes entre 0° y 85°.
- Grupo 2, imágenes entre 90° y 175°.
- Grupo 3, imágenes entre 180° y 265°.
- Grupo 4, imágenes entre 270° y 355°.
Al igual que en el esquema anterior, también se realizaron 5 niveles de pruebas. En estos niveles se consideraron diferente número de imágenes para realizar el entrenamiento y su respectiva evaluación. Por lo que en este esquema se formaron los siguientes subgrupos, tomando aleatoriamente la cantidad de imágenes para entrenamiento y prueba que se indica a continuación:
- 3 imágenes de cada grupo para entrenamiento y 8 imágenes para prueba.
- 5 imágenes de cada grupo para entrenamiento y 8 imágenes para prueba.
- 7 imágenes de cada grupo para entrenamiento y 8 imágenes para prueba.
- 9 imágenes de cada grupo para entrenamiento y 8 imágenes para prueba.
- 10 imágenes de cada grupo para entrenamiento y 8 imágenes para prueba.
Por lo tanto, en el segundo esquema se tomaron respectivamente 12, 20, 28, 36 y 40 imágenes para entrenamiento y en cada caso 32 imágenes distintas para pruebas.
Obviamente, para cada uno de los esquemas se hizo la selección de los vectores de características de las imágenes de los objetos respectivos tanto para el entrenamiento de la red neuronal como para la evaluación. Esto con la finalidad de obtener el porcentaje de reconocimiento y poder establecer el parámetro de reconocimiento del sistema implementado. Para ello se realizaron en total 100 combinaciones de entrenamiento y pruebas, derivados de los esquemas descritos en los párrafos anteriores.
A partir de las pruebas realizadas con la validación cruzada se obtuvieron los resultados que a continuación se enlistan:
- Durante las iteraciones realizadas el peor porcentaje de reconocimiento que se obtuvo fue del 76 % y el mejor llegó a 89 %.
- De acuerdo con el esquema utilizado, ya sea 1 o 2, el promedio de reconocimiento oscila entre el 82.6 % y el 83.8 %, resultado que se muestra en la Figura 9.
- Tomando en cuenta el nivel de prueba y la cantidad de imágenes utilizadas para realizar el entrenamiento. el promedio de reconocimiento obtenido está en el rango del 80.8 % al 84.06 % tal y como se muestra en la Figura 10.
- El promedio de reconocimiento del número de iteraciones, 10 en este caso, se muestra en la Figura 11, dando como resultado promedio de reconocimiento en el rango del 81.3% al 83.9%.
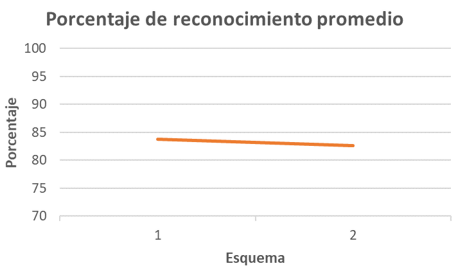
Figura 9. Tasa de reconocimiento según el esquema usado. Fuente: elaboración propia
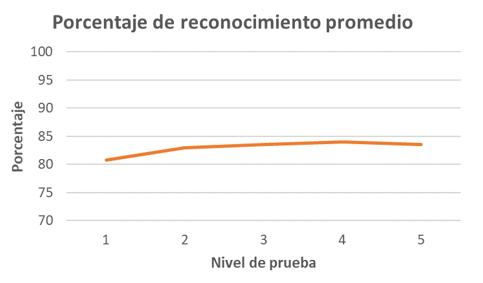
Figura 10. Tasa de reconocimiento según el nivel de prueba. Fuente: elaboración propia
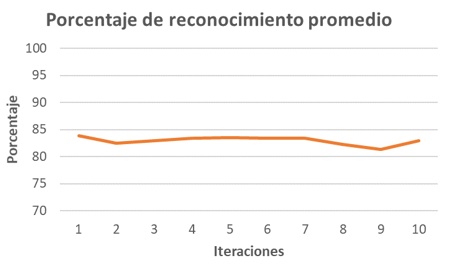
Figura 11. Tasa de reconocimiento según al número de iteración. Fuente: elaboración propia
Finalmente, a partir de los resultados obtenidos, se puede comentar que el sistema es robusto y estable. Esto debido a que el porcentaje de reconocimiento obtenido está en el rango de los valores obtenidos en los experimentos mostrados en las secciones de Evaluación y Reconocimiento usando conjuntos pequeños de entrenamiento, lo que que valida los resultados obtenidos por el sistema de reconocimiento implementado.
Conclusiones
En este trabajo se mostró cómo el sistema de reconocimiento de objetos formado por HOG y SOM es capaz de alcanzar un buen porcentaje de reconocimiento. Además, una vez que ha sido configurado, es muy estable respecto a las imágenes que se utilicen para entrenamiento. Otra ventaja es que el mapa autoorganizado automáticamente asociará a la misma clase a los objetos con características geométricas similares.
A partir de los resultados obtenidos, las principales contribuciones que se hacen en este trabajo son:
- Se propone un esquema de reconocimiento de objetos basado en un mapa autoorganizado que funciona con base en las características geométricas de los objetos.
- Se muestra que el mapa autoorganizado tiene la capacidad para agrupar objetos con características geométricas similares.
- Se muestra que el sistema es capaz de reconocer características de objetos similares usando en la fase de aprendizaje un porcentaje pequeño de estas.
- Se demuestra que el sistema propuesto es estable.
Además, los resultados que se obtuvieron con la configuración propuesta demuestran un desempeño robusto con una tasa de reconocimiento que oscila entre el 80% y el 85%. Este es un buen porcentaje de reconocimiento considerando que no se aplicó ningún tipo de optimización ni en las imágenes de los objetos ni sobre el descriptor.
Finalmente, se comenta que el sistema muestra que es capaz de aprender las características de objetos similares con un conjunto pequeño de imágenes respecto del total.
Referencias
1. DALAL, N. and TRIGGS, B., 2005, Histograms of oriented gradients for human detection. 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05). 2005, San Diego, CA, USA. [En línea]. Vol. 1, p. 886-893. [Fecha de consulta: 5 de marzo de 2021]. Disponible en https://ieeexplore.ieee.org/document/1467360 ISSN: 1063-6919
2. KOHONEN, T. The self-organizing map. Proceedings of the IEEE.. Vol. 78, no. 9, p. 1464-1480. 1990. DOI 10.1109/5.58325. Institute of Electrical and Electronics Engineers (IEEE)
3. NENE, S.A., NAYAR, S.K. and MURASE, H. Columbia Object Image Library (COIL-100) . Technical Report CUCS-006-96. 1996. p. 1-6. Columbia University. [Fecha de consulta: 5 de julio de 2021]. Disponible en https://www.cs.columbia.edu/CAVE/software/softlib/coil-20.php
4. MODEL, I. and SHAMIR, L. Comparison of data set bias in object recognition benchmarks. IEEE Access . 2015. Vol. 3, p. 1953-1962. DOI 10.1109/access.2015.2491921. Institute of Electrical and Electronics Engineers (IEEE). ISSN: 2169-3536.
5. DENG, L., WANG, Y., LIU, B., LIU, WEIFENG and QI, Y., Biological modeling of human visual system for object recognition using GLoP filters and sparse coding on multi-manifolds. Machine Vision and Applications. 2018. Vol. 29, no. 6, p. 965-977. DOI 10.1007/s00138-018-0928-9. Springer Science and Business Media LLC.
6. LI DENG, 2012. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Processing Magazine. noviembre 2012. Vol. 29, no. 6, p. 141-142. DOI 10.1109/MSP.2012.2211477. ISSSN: 1053-5888
7. BHADANE, Jayesh; MHATRE, Chetan y CHAUDHARI, Arvind. Object Detection using Hausdorff distance. International Research Journal of Engineering and Technology (IRJET). 2020. Vol. 07, no. 04, p. 4. ISSN: 2395-0056
8. KUMAR, K. S., MANIGANDAN, T., CHITRA, D. and MURALI, L. Object recognition using Hausdorff distance for multimedia applications. Multimedia Tools and Applications. 2020. Vol. 79, no. 5-6, p. 4099-4114. Springer Science and Business Media LLC. Disponible en https://doi.org/10.1007/s11042-019-07774-z
9. OU, Jun, LI, Yujian y LIU, Wei, TDP: Two-dimensional perceptron for image recognition. Knowledge-Based Systems. Vol. 195, p. 105615. 11 de mayo 2020. DOI 10.1016/j.knosys.2020.105615.
10. FANG, Chieh-Ning y LIN, Chin-Teng, Multi-Subspace Neural Network for Image Recognition. Arxiv Cornell University. En línea]. Vol. abs/2006.09618. 17 de junio de 2020. [Fecha de consulta: 5 de junio de 2021]. Recuperado a partir de https://arxiv.org/abs/2006.09618
11. HUANG, Wenkai y ZHOU, Fobao. DA-CapsNet: dual attention mechanism capsule network. Scientific Reports. diciembre 2020. Vol. 10, no. 1, p. 11383. Diciembre 2020. DOI 10.1038/s41598-020-68453-w.
12. MEERA, M.K. and MOHAN SHAJEE, B.S. Object recognition in images. 2016 International Conference on Information Science (ICIS). Kochi, India. 12-13 de agosto de 2016. P. 126-130. DOI 10.1109/infosci.2016.7845313. ISBN: 978-1-5090-1988-5
13. EL MALLAHI, M., ZOUHRI, A., EL AFFAR, A., TAHIRI, A. and QJIDAA, H. Radial Hahn Moment Invariants for 2D and 3D Image Recognition. International Journal of Automation and Computing. Vol. 15, no. 3, p. 277-289. 21de junio de 2017. DOI 10.1007/s11633-017-1071-1.
14. YANG, J., ZHANG, L. and LI, P. Radon–Fourier descriptor for invariant pattern recognition. International Journal of Wavelets, Multiresolution and Information Processing. Vol. 17, núm. 02, p. 1940004. 2019. DOI 10.1142/s0219691319400046. ISSN: 0219-6913
15. MOHAN, B Chandra, CHAITANYA, T Krishna y TIRUPAL, T, Fast and Accurate Content Based Image Classification and Retrieval using Gaussian Hermite Moments applied to COIL 20 and COIL 100. En 10th International Conference on Computing, Communication and Networking Technologies (ICCCNT). 6-8 de julio de 2019. Kanpur, India. Institute of Electrical and Electronics Engineers. ISBN: 978-1-5386-5907-6
16. PESTEIE, Mehran, ABOLMAESUMI, Purang y ROHLING, Robert, 2018. Deep Neural Maps. Arxiv Cornell University. [En línea]. 16 octubre 2018. [Fecha de consulta: 10 de diciembre de 2021]. Recuperado a partir de: http://arxiv.org/abs/1810.07291
17. CHENNIAPPAN, Thilagavathy y REGHUNADHAN, Rajesh. Rough Image Based Ensemble of Convolutional Neural Networks for Object Recognition. International Journal of Engineering Research and Technology. Vol. 12, no. 6, p. 7. 2019. ISSN: 0974-3154
18. SACCO, Ludovica, IENCO, Dino e INTERDONATO, Roberto. A neural network strategy for supervised classification via the Learning Under Privileged Information paradigm. SEBD 2021: The 29th Italian Symposium on Advanced Database System. Septiembre 5-9 de 2021, Pizza Calabro, Italia.
19. PRABHU, V. S., RAJESWARI, P. y BLESSY, Y. M. A Novel Method for Object Recognition with a Modified Pulse Coupled Neural Network. En: SENGODAN, Thangaprakash, MURUGAPPAN, M. y MISRA, Sanjay (eds.), Advances in Electrical and Computer Technologies. Singapore: Springer. 2021. p. 521-531. Lecture Notes in Electrical Engineering. ISBN 9789811590191.
20. QARAEI, Mohammadreza, ABBAASI, Saeid y GHIASI-SHIRAZI, Kamaledin Randomized non-linear PCA networks. Information Sciences. Vol. 545, p. 241-253. 4 febrero 2021. DOI 10.1016/j.ins.2020.08.005.
21. KIM, Younghoon, LEE, Minjung y KIM, Seoung Bum. Swarm ascending: Swarm intelligence-based exemplar group detection for robust clustering. Applied Soft Computing. Vol. 102, p. 107062. 1 de abril de 2021. DOI 10.1016/j.asoc.2020.107062.
22. OpenCV: cv::HOGDescriptor Struct Reference. 2021. Docs.opencv.org [online].
| Fecha de recepción | Fecha de aceptación | Fecha de publicación |
|---|---|---|
| 05-07-2021 | 11/02/2022 | 31/05/2022 |
| Año 9, Número 3. Mayo - Agosto, 2022. | ||



