Clasificación de sonidos mediante el análisis de imágenes bidimensionales del espectro de frecuencias
Por: Valentín Calzada Ledesma, Raúl Santiago Montero, Manuel Ornelas Rodríguez
Resumen
El procesamiento digital de señales sonoras consiste en la manipulación matemática de las mismas. La finalidad es obtener información que puede ser utilizada en distintas aplicaciones, como la clasificación y el reconocimiento de sonido. Las técnicas empleadas para describir las señales sonoras, en términos de procesamiento de señales, no son sencillas de implementar, así mismo, su simulación en computadora implica un alto costo computacional. Este trabajo propone un enfoque diferente para realizar el análisis de señales sonoras, mediante el estudio de imágenes bidimensionales del espectro de frecuencias del sonido, utilizando técnicas de visión por computadora para analizar y obtener vectores de características de las mismas y posteriormente realizar la clasificación de estos vectores con algoritmos de reconocimiento de patrones, como K-Nearest Neighbor y Naïve Bayes. Para las muestras de sonido utilizadas, se lograron porcentajes de exactitud promedio superiores al 85%.
Palabras clave: Reconocimiento de patrones, visión por computadora, espectro de frecuencias del sonido, K-Nearest Neighbor, Naïve Bayes.
Abstract
The digital signal processing is a line of research whose goal is to provide information from signals such as sound, where some applications are classification and recognition. The techniques used to describe the sound signals in terms of signal processing, are not easy to implement, also, the computer simulation involves a lot of computational resources. This paper proposes a different approach to the sound signals analysis, by means of the study for two-dimensional images of the sound frequency spectrum, by using computer vision techniques to analyze and get feature vectors. Finally, the classification approach of these vectors is performed by the pattern recognition algorithms such as K -Nearest Neighbor and Naïve Bayes. For sound samples used, average accuracy rates were above 87%.
El ser humano ha tratado de reproducir artificialmente algunas de las habilidades sensoriales que poseen los seres vivos, entre ellas, los procesos de percepción auditiva y visual. Los organismos biológicos poseen ciertas características y/o habilidades que se encuentran en constante desarrollo, y que, conforme se desenvuelven en la vida, adquirieren un conocimiento general sobre su entorno (acotado a su capacidad sensorial), el cual les permite adaptarse a las diversas situaciones que acontezcan durante su existencia.
En la actualidad, existe una línea de investigación llamada Inteligencia Artificial (IA), la cual busca, entre otros propósitos, dotar de autonomía a agentes inteligentes (como un robot), los cuales se pretende que interactúen con su entorno sin la necesidad de intervención humana. Algunos de los principales problemas que la IA ha tratado de solucionar, se centran en la clasificación y reconocimiento, ya sea de objetos o voz, o dicho de otro modo, la clasificación y reconocimiento de patrones en imágenes y sonido.
Por una parte, la clasificación de sonido se centra en el análisis de señales sonoras, las cuales generalmente son tratadas mediante técnicas de procesamiento de señales, cuyos algoritmos se enfocan en el análisis matemático y físico de la señal. Posteriormente se obtienen los patrones de la señal sonora y estos son clasificados.
Por otro lado, el análisis de imágenes se centra en estudiar regiones (escenas) de interés en las mismas. Para realizar dicho estudio, se utilizan técnicas de visión por computadora, estas tratan de describir el mundo que vemos en una o más imágenes y así reconstruir sus propiedades, tales como la forma, iluminación, distribuciones de color, etcétera, en donde el objetivo principal consiste en modelar computacionalmente los procesos de percepción visual de los seres vivos.
En este artículo, se propone combinar estas dos tendencias de la IA, cuya hipótesis planteada, a manera de pregunta, es la siguiente: ¿Es posible realizar clasificación de sonidos mediante el análisis de imágenes del espectro de frecuencias de los mismos?
El objetivo de este artículo es dar a conocer los resultados obtenidos mediante la metodología sugerida, de la cual (debe decirse), es una propuesta inicial, de manera que no es un método general. El método propuesto consiste en el análisis de señales sonoras mediante imágenes bidimensionales, de las cuales, se obtendrán los descriptores esenciales con los que se formarán vectores de características (patrón) que describirán una señal sonora, estos fungirán como materia prima para los algoritmos de reconocimiento de patrones. Las imágenes a analizar corresponden a la gráfica del espectro de frecuencias del sonido, elemento comúnmente utilizado en los procesos de reconocimiento de voz. A grandes rasgos, este trabajo aborda el análisis de sonido, su descripción computacional y su clasificación, desde una perspectiva diferente: la de la visión por computadora.
2. Conceptos teóricos
Para entrar en contexto, se definirán algunos de los conceptos y herramientas utilizadas durante el desarrollo de este trabajo.
2.1 Sonido
El sonido es un fenómeno vibratorio que es transmitido en forma de ondas a través de diversos medios elásticos, entre los más comunes se encuentran el aire y el agua.1 El ser humano es capaz de percibir y distinguir distintos tipos de sonidos entre los 20 Hz y los 20 kHz. Así mismo, existen diversas cualidades que modifican el espectro audible, estas son: intensidad, tono y timbre.
2.2 Espectro de frecuencias del sonido
Visualmente, el espectro de frecuencias muestra una forma de onda por sus intensidades de componentes de frecuencia, donde el eje y (vertical) mide la frecuencia y el eje x (horizontal) mide el tiempo. El espectro permite además analizar los datos de la señal, para visualizar las frecuencias que son numéricamente más extendidas2.
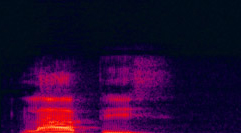
A continuación se muestra el espectro de frecuencias de la voz de un varón adulto, cuyo mensaje es “Eres única”. Los colores más claros (naranja-amarillo) representan componentes de amplitud mayores y los colores inician desde el azul oscuro (frecuencias de baja amplitud).
Fig 1. Espectro de frecuencias del mensaje “Eres única”.
2.3 Componentes de un sistema de reconocimiento
Desde el punto de vista de la visión por computadora, un sistema de reconocimiento permite a un agente inteligente reconocer ciertos patrones en imágenes bidimensionales mediante el uso de algoritmos computacionales. El sistema de reconocimiento se compone de diferentes etapas, las cuales, de acuerdo con la necesidad o problema, se pueden modificar y/o adaptar para su mejor solución. No todas las etapas son obligatorias, ya que la complejidad del problema es la que dictamina el tipo de herramientas que se utilizarán. A continuación se enuncian las etapas de aplicación de un sistema de reconocimiento3:
Adquisición de imágenes: es la recopilación de la materia prima a analizar, mediante algún dispositivo de captura (cámara, escáner, etcétera).
Pre-tratamiento de imágenes: consiste de una serie de técnicas cuyo objetivo es mejorar la apariencia visual de una imagen (en caso de que la requiera) para su posterior segmentación.
Segmentación: su objetivo es simplificar y/o cambiar la representación de una imagen en otra más significativa y más fácil de analizar.
Representación o descripción: el objetivo de esta etapa es encontrar una representación cuantitativa de una imagen, que sea analizable a través de una computadora.
Reconocimiento: consiste en la asignación de una etiqueta a un determinado valor de entrada. Un ejemplo de reconocimiento de patrones es la clasificación, que pretende asignar cada valor de entrada a uno de un conjunto dado de clases.
2.4 Descriptores mediante la modificación del histograma
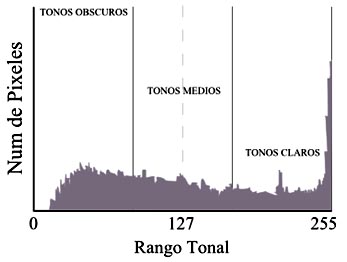
El histograma de una imagen es un gráfico que ofrece una descripción global de la apariencia de la imagen. En el eje de las abscisas se representa el rango de valores de píxeles de la imagen, mientras que en el eje de ordenadas se representa el rango de valores que pueden tomar esos píxeles.4
Fig 2. Histograma de una imagen.
En una imagen es visualmente claro que no existe mucha diferencia entre los tonos más claros y más oscuros. Mediante distintas operaciones matemáticas podemos transformar esos valores de grises en otros, con un rango mayor que se adapte plenamente a la capacidad del dispositivo de visualización, estas operaciones matemáticas son la probabilidad de ocurrencia, la media, la varianza, la energía y la entropía de una imagen, los cuales se utilizarán como descriptores de las imágenes. A continuación se muestra cómo se realiza el cálculo de cada uno de estos.
2.4.1 Probabilidad de ocurrencia de un nivel de gris en una imagen
(1)
Donde N(g) es el número de pixeles con un nivel de gris g y M es el total de pixeles de la imagen.
2.4.2 Mediana en una imagen
La mediana nos ofrece información sobre el nivel de brillo de una imagen.
(2)
donde x es el número de filas en la imagen, y es el número de columnas en la imagen, L es el total de niveles de gris, M es el total de pixeles de la imagen.
2.4.3 Varianza en una imagen
La varianza nos ofrece información del contraste de la imagen.
(3)
2.4.4 Energía en una imágen
La energía informa sobre el número de niveles de gris utilizados por una imagen.
(4)
2.4.5 Entropía en una imagen
La entropía es una magnitud que permite determinar la parte de la energía que no puede utilizarse para producir trabajo.
(5)
2.5 Enfoques de reconocimiento de patrones
El reconocimiento de patrones es la asignación de una etiqueta a un determinado valor de entrada. Un ejemplo de reconocimiento de patrones es la clasificación que pretende asignar cada valor de entrada a uno de un conjunto dado de clases. Para realizar los procesos de clasificación, existen diferentes algoritmos clasificadores supervisados, como el K-Nearest Neighbor y el Naïve Bayes.5
2.5.1 K- Nearest Neighbor
Consideremos m clases y un conjunto N de patrones de muestra , cuya clasificación es conocida a priori. Sea x un patrón arbitrario entrante, el enfoque de Nearest Neighbor (“vecino más cercano”) asigna a x a la clase donde el patrón se encuentra más cerca del conjunto , es decir, si
(6)
entonces . Este esquema es básicamente otro tipo de clasificación por mínima distancia, se puede modificar mediante la consideración de los k vecinos más cercanos a x y el uso de un clasificador tipo regla-mayoritaria.6
2.5.2 Naïve Bayes
Consideremos un número finito de clases {C1,C2,…,Cm} y un vector característico x en Rn. Cada componente de este vector es una característica escalar significativa de Ci,1 ≤ i ≤m. El vector característico es una variable aleatoria dada una distribución de probabilidad condicional p (x | C i ),1 ≤ i ≤ m. Si denotamos a p ( x | C i ) como la probabilidad a priori que tiene un patrón entrante de pertenecer a una clase C i, entonces la probabilidad a posteriori de este patrón con un vector característico adjunto x para pertenecer a C i, está dada por la siguiente fórmula de Bayes:7
(7)
donde
(8)
es la probabilidad de distribución de x
2.6 Matriz de confusión y porcentaje de exactitud
En los algoritmos de reconocimiento de patrones, la matriz de confusión es una herramienta de visualización que se emplea en aprendizaje supervisado. Cada columna de la matriz representa el número de predicciones de cada clase, mientras que cada fila representa a las instancias en la clase real. Uno de los beneficios de las matrices de confusión es que facilitan ver si el sistema está confundiendo dos o más clases. La Tabla 1 muestra un ejemplo de matriz de confusión.
Clase verdadera
C1
C2
C3
Clase predicha
C1
VC1
FC2
FC3
C2
FC1
VC2
FC3
C3
FC1
FC2
VC3
Tabla 1. Matriz de confusión
En donde Cn representan las clases a clasificar, VCn representan las clases verdaderas que son correctamente clasificadas y FCnclases falsas que no son correctamente clasificadas.
La exactitud (Exc), es la proporción del número total de predicciones que fueron correctas divididas por el total de muestras (Tm) y multiplicadas por 100 Se determina mediante la siguiente ecuación8:
(9)
2.7 Validación cruzada
En la validación cruzada k-fold (también llamada estimación de rotación) la base de datos D es dividida aleatoriamente en K subconjuntos exclusivos (las particiones) D1,D2,… Dk aproximadamente del mismo tamaño. El inductor es entrenado y probado K veces; cada vez t ∈ {1, 2, …, K}, es entrenado sobre D \ Dt y probado sobre Dt . La validación cruzada estima la exactitud del número total de clasificaciones correctas, dividido por el número de instancias en la base de datos. Formalmente, D(i) es el conjunto de pruebas que incluye instancias xi = vi ,yi , entonces la validación cruzada estima la exactitud:
(10)
La validación cruzada estimada es un número aleatorio que depende de la división en las particiones. La validación cruzada completa 9 es el promedio de todas las posibilidades para seleccionar m/K instancias de m.
3. Desarrollo
A continuación se enunciarán los pasos utilizados durante el desarrollo de este trabajo, en donde básicamente se siguieron las etapas del proceso de reconocimiento.
3.1 Captura
El primer paso consistió en la captura de audio, esta se realizó con un micrófono AKG Perception 220 conectado a una interfaz Profire 2626 m-audio y esta a su vez a una computadora con un software de captura y edición de audio. Se realizaron 120 capturas diferentes divididas en tres clases o tipos de sonidos.
Las clases son: Voz, tambores y platillos.
Muestras
Clase 1
Clase 2
Clase 3
Tipos de voz
Tipos de tambores
Tipos de platillos
Hombre
Tom 12”
Hi-hats 14”
Mujer
Tom 13”
Crash 16”
Tom 16”
Crash 18”
Tarola
Ride 20”
Bombo
Splash 12”
Tabla 2. Muestras de audio capturadas.
Una vez capturadas las 120 muestras de audio, se procedió a obtener las imágenes del espectro de frecuencias de las mismas. Éstas se obtuvieron utilizando el mismo software de captura. Al final, se tienen 120 imágenes, 40 para cada clase de objetos.
3.2 Tratamiento y segmentación
Como las imágenes por su naturaleza son de fondo negro y la gráfica del espectro de frecuencias con varias intensidades de color (rojo, naranja y púrpura), no se requirió un tratamiento de las imágenes, así mismo, la segmentación de una imagen consiste en invertir la misma y convertirla a escala de grises. A continuación se muestran las imágenes que describen el proceso:
a)
b)
c)
Fig 3. Imágenes correspondientes al proceso de segmentación, a) imagen original, b) imagen invertida, c) imagen en escala de grises.
3.3 Caracterización
Una vez segmentadas las 120 imágenes, se prosiguió a realizar el cálculo de los descriptores de la imagen, en este caso, el vector de características (Vc ) para cada imagen queda conformado por los descriptores mencionados en los conceptos teóricos y se ordenan de la siguiente manera:
(11)
donde es la mediana, σ² es la varianza. E es la energía y e es la entropía.
Una vez caracterizadas las 120 imágenes, se almacenaron cada uno de los vectores de características (cada uno de dimensión R⁴) en una base de datos llamada “ImageData”, la cual consta de 120 tuplas y 4 atributos (120X4). Cabe señalar que la base de datos está diseñada de la misma manera que las bases de datos Iris Plant y Wine, ambas pertenecientes al repositorio “UCI Machine Learning Repository”, las cuales son bases de datos diseñadas para probar algoritmos de reconocimiento de patrones, ambas utilizadas en gran parte del estado del arte; estas cuentan con 150 tuplas y 4 atributos. Así mismo, el diseño de la base de datos se realizó de esta manera ya que lo que se pretende con este trabajo es probar la hipótesis inicial, la del reconocimiento de sonidos mediante imágenes.
3.4 Proceso de clasificación
Por último, se realizó la clasificación de los patrones (incluidos en la base de datos) utilizando los algoritmos de clasificación supervisada K-Nearest Neighbor (con un valor de k=1) y Naïve Bayes. Así mismo, con la finalidad de verificar la integridad de la base de datos y el desempeño de cada uno de los algoritmos, se utilizó la validación cruzada 10, en donde se realizaron 10 particiones (K-folds) para la selección de las muestras para su entrenamiento y recuperación. Las pruebas de clasificación se realizaron para la base de datos ImageData.
4. Resultados
A continuación se muestran las tablas con los resultados obtenidos, utilizando la validación cruzada, en estas se muestra cada partición (K-fold) correspondiente y su porcentaje de exactitud asociado:
K-Nearest Neighbor
Naïve Bayes
1
88.2
1
89.7
2
85.1
2
92.3
3
85.1
3
92.3
4
84.3
4
92.3
5
88.3
5
91.0
6
85.2
6
92.3
7
88.2
7
93.5
8
91.0
8
92.3
9
87.1
9
93.5
10
91.0
10
91.0
Exactitud promedio
87.35
Exactitud promedio
92.05
Tabla 3. Resultados de exactitud para KNN
Tabla 4. Resultados de exactitud para NB
Conclusiones
Con el desarrollo de este trabajo se verificó la hipótesis inicial, en donde se concluye que es posible clasificar sonidos a través del análisis de la imagen del espectro de frecuencias tomando como descriptores la media, varianza, energía y entropía. También, se pueden enumerar las siguientes conclusiones, de acuerdo al análisis de los resultados.
1. Los descriptores propuestos para generar el vector de características, cuya tarea fue la de caracterizar cada una de las imágenes del espectro de frecuencias del sonido, resultaron adecuados para realizar los procesos de clasificación, sin embargo, se debe profundizar más en el comportamiento de los mismos, para identificar posibles correlaciones.
2. A través de la validación cruzada se concluye que, para este trabajo, bajo las condiciones establecidas (tratamiento, segmentación y caracterización), el algoritmo de mejor desempeño fue Naïve Bayes, ofreciendo un porcentaje de clasificación promedio del 92.05% en las pruebas realizadas.
Como trabajo futuro, se propone explorar con otras técnicas para segmentar las imágenes, así como el uso de diferentes descriptores para caracterizar las mismas, además es recomendable aumentar la población de vectores característicos y el número de clases, con la finalidad de lograr mejorar los resultados presentados en este artículo y robustecer el método.
Referencias
1. SCHIFFMAN, Harvey. La Percepción Sensorial. (2001). Limusa Wiley. p. 72. ISBN 968-18-5307-5.
2. . Baughman RP, Sound spectral analysis of voice-transmitted sound, Loudon RG, The American Review of Respiratory Disease [1986, 134(1):167-169].
3. GONZÁLEZ, Rafael C. and WOODS, Richard E. Digital image processing. Prentice Hall, New Jersey, 2 edition, 2002b. pp. 25-30.
4.
GONZÁLEZ, Rafael C. and WOODS, Richard E, op cit, p. 88.
5. CALZADA, Valentín y ORNELAS, Manuel. Análisis de componentes principales aplicados al reconocimiento de objetos 3D bajo rotación, Research in computing science, Vol. 62, pp. 197-206, ISSN: 1870-4069.
6. FRIEDMAN, MENAHEM, KANDEL and ABRAHAM. Introduction to pattern recognition: statistical, structural, neural, and fuzzy logic approaches. Volume 32 of Series in machine perception and artificial intelligence. Singapore River Edge, N.J. World Scientific, 1999. ISBN 981-023312-4. p. 65, p. 106.
7. FRIEDMAN et al, op cit.
8. FAWCETT, Tom. An introduction to ROC analysis. Pattern Recognition Letters, 27:861–874, 2006.
9. KOHAVI, Ron. A study of cross-validation and bootstrap for accuracy estimation and model selection. International joint conference on artificial intelligence (IJCAI), 1995.
10. KOHAVI, Ron, op cit.
El procesamiento digital de señales sonoras consiste en la manipulación matemática de las mismas. La finalidad es obtener información que puede ser utilizada en distintas aplicaciones, como la clasificación y el reconocimiento de sonido. Las técnicas empleadas para describir las señales sonoras, en términos de procesamiento de señales, no son sencillas de implementar, así mismo, su simulación en computadora implica un alto costo computacional. Este trabajo propone un enfoque diferente para realizar el análisis de señales sonoras, mediante el estudio de imágenes bidimensionales del espectro de frecuencias del sonido, utilizando técnicas de visión por computadora para analizar y obtener vectores de características de las mismas y posteriormente realizar la clasificación de estos vectores con algoritmos de reconocimiento de patrones, como K-Nearest Neighbor y Naïve Bayes. Para las muestras de sonido utilizadas, se lograron porcentajes de exactitud promedio superiores al 87%.
Palabras clave: Reconocimiento de patrones, visión por computadora, espectro de frecuencias del sonido, K-Nearest Neighbor, Naïve Bayes.
Abstract
The digital signal processing is a line of research whose goal is to provide information from signals such as sound, where some applications are classification and recognition. The techniques used to describe the sound signals in terms of signal processing, are not easy to implement, also, the computer simulation involves a lot of computational resources. This paper proposes a different approach to the sound signals analysis, by means of the study for two-dimensional images of the sound frequency spectrum, by using computer vision techniques to analyze and get feature vectors. Finally, the classification approach of these vectors is performed by the pattern recognition algorithms such as K -Nearest Neighbor and Naïve Bayes. For sound samples used, average accuracy rates were above 87%.
El ser humano ha tratado de reproducir artificialmente algunas de las habilidades sensoriales que poseen los seres vivos, entre ellas, los procesos de percepción auditiva y visual. Los organismos biológicos poseen ciertas características y/o habilidades que se encuentran en constante desarrollo, y que, conforme se desenvuelven en la vida, adquirieren un conocimiento general sobre su entorno (acotado a su capacidad sensorial), el cual les permite adaptarse a las diversas situaciones que acontezcan durante su existencia.
En la actualidad, existe una línea de investigación llamada Inteligencia Artificial (IA), la cual busca, entre otros propósitos, dotar de autonomía a agentes inteligentes (como un robot), los cuales se pretende que interactúen con su entorno sin la necesidad de intervención humana. Algunos de los principales problemas que la IA ha tratado de solucionar, se centran en la clasificación y reconocimiento, ya sea de objetos o voz, o dicho de otro modo, la clasificación y reconocimiento de patrones en imágenes y sonido.
Por una parte, la clasificación de sonido se centra en el análisis de señales sonoras, las cuales generalmente son tratadas mediante técnicas de procesamiento de señales, cuyos algoritmos se enfocan en el análisis matemático y físico de la señal. Posteriormente se obtienen los patrones de la señal sonora y estos son clasificados.
Por otro lado, el análisis de imágenes se centra en estudiar regiones (escenas) de interés en las mismas. Para realizar dicho estudio, se utilizan técnicas de visión por computadora, estas tratan de describir el mundo que vemos en una o más imágenes y así reconstruir sus propiedades, tales como la forma, iluminación, distribuciones de color, etcétera, en donde el objetivo principal consiste en modelar computacionalmente los procesos de percepción visual de los seres vivos.
En este artículo, se propone combinar estas dos tendencias de la IA, cuya hipótesis planteada, a manera de pregunta, es la siguiente: ¿Es posible realizar clasificación de sonidos mediante el análisis de imágenes del espectro de frecuencias de los mismos?
El objetivo de este artículo es dar a conocer los resultados obtenidos mediante la metodología sugerida, de la cual (debe decirse), es una propuesta inicial, de manera que no es un método general. El método propuesto consiste en el análisis de señales sonoras mediante imágenes bidimensionales, de las cuales, se obtendrán los descriptores esenciales con los que se formarán vectores de características (patrón) que describirán una señal sonora, estos fungirán como materia prima para los algoritmos de reconocimiento de patrones. Las imágenes a analizar corresponden a la gráfica del espectro de frecuencias del sonido, elemento comúnmente utilizado en los procesos de reconocimiento de voz. A grandes rasgos, este trabajo aborda el análisis de sonido, su descripción computacional y su clasificación, desde una perspectiva diferente: la de la visión por computadora.
2. Conceptos teóricos
Para entrar en contexto, se definirán algunos de los conceptos y herramientas utilizadas durante el desarrollo de este trabajo.
2.1 Sonido
El sonido es un fenómeno vibratorio que es transmitido en forma de ondas a través de diversos medios elásticos, entre los más comunes se encuentran el aire y el agua.1 El ser humano es capaz de percibir y distinguir distintos tipos de sonidos entre los 20 Hz y los 20 kHz. Así mismo, existen diversas cualidades que modifican el espectro audible, estas son: intensidad, tono y timbre.
2.2 Espectro de frecuencias del sonido
Visualmente, el espectro de frecuencias muestra una forma de onda por sus intensidades de componentes de frecuencia, donde el eje y (vertical) mide la frecuencia y el eje x (horizontal) mide el tiempo. El espectro permite además analizar los datos de la señal, para visualizar las frecuencias que son numéricamente más extendidas2.
A continuación se muestra el espectro de frecuencias de la voz de un varón adulto, cuyo mensaje es “Eres única”. Los colores más claros (naranja-amarillo) representan componentes de amplitud mayores y los colores inician desde el azul oscuro (frecuencias de baja amplitud).
Fig 1. Espectro de frecuencias del mensaje “Eres única”.
2.3 Componentes de un sistema de reconocimiento
Desde el punto de vista de la visión por computadora, un sistema de reconocimiento permite a un agente inteligente reconocer ciertos patrones en imágenes bidimensionales mediante el uso de algoritmos computacionales. El sistema de reconocimiento se compone de diferentes etapas, las cuales, de acuerdo con la necesidad o problema, se pueden modificar y/o adaptar para su mejor solución. No todas las etapas son obligatorias, ya que la complejidad del problema es la que dictamina el tipo de herramientas que se utilizarán. A continuación se enuncian las etapas de aplicación de un sistema de reconocimiento3:
Adquisición de imágenes: es la recopilación de la materia prima a analizar, mediante algún dispositivo de captura (cámara, escáner, etcétera).
Pre-tratamiento de imágenes: consiste de una serie de técnicas cuyo objetivo es mejorar la apariencia visual de una imagen (en caso de que la requiera) para su posterior segmentación.
Segmentación: su objetivo es simplificar y/o cambiar la representación de una imagen en otra más significativa y más fácil de analizar.
Representación o descripción: el objetivo de esta etapa es encontrar una representación cuantitativa de una imagen, que sea analizable a través de una computadora.
Reconocimiento: consiste en la asignación de una etiqueta a un determinado valor de entrada. Un ejemplo de reconocimiento de patrones es la clasificación, que pretende asignar cada valor de entrada a uno de un conjunto dado de clases.
2.4 Descriptores mediante la modificación del histograma
El histograma de una imagen es un gráfico que ofrece una descripción global de la apariencia de la imagen. En el eje de las abscisas se representa el rango de valores de píxeles de la imagen, mientras que en el eje de ordenadas se representa el rango de valores que pueden tomar esos píxeles.4
Fig 2. Histograma de una imagen.
En una imagen es visualmente claro que no existe mucha diferencia entre los tonos más claros y más oscuros. Mediante distintas operaciones matemáticas podemos transformar esos valores de grises en otros, con un rango mayor que se adapte plenamente a la capacidad del dispositivo de visualización, estas operaciones matemáticas son la probabilidad de ocurrencia, la media, la varianza, la energía y la entropía de una imagen, los cuales se utilizarán como descriptores de las imágenes. A continuación se muestra cómo se realiza el cálculo de cada uno de estos.
2.4.1 Probabilidad de ocurrencia de un nivel de gris en una imagen
(1)
Donde N(g) es el número de pixeles con un nivel de gris g y M es el total de pixeles de la imagen.
2.4.2 Mediana en una imagen
La mediana nos ofrece información sobre el nivel de brillo de una imagen.
(2)
donde x es el número de filas en la imagen, y es el número de columnas en la imagen, L es el total de niveles de gris, M es el total de pixeles de la imagen.
2.4.3 Varianza en una imagen
La varianza nos ofrece información del contraste de la imagen.
(3)
2.4.4 Energía en una imágen
La energía informa sobre el número de niveles de gris utilizados por una imagen.
(4)
2.4.5 Entropía en una imagen
La entropía es una magnitud que permite determinar la parte de la energía que no puede utilizarse para producir trabajo.
(5)
2.5 Enfoques de reconocimiento de patrones
El reconocimiento de patrones es la asignación de una etiqueta a un determinado valor de entrada. Un ejemplo de reconocimiento de patrones es la clasificación que pretende asignar cada valor de entrada a uno de un conjunto dado de clases. Para realizar los procesos de clasificación, existen diferentes algoritmos clasificadores supervisados, como el K-Nearest Neighbor y el Naïve Bayes.5
2.5.1 K- Nearest Neighbor
Consideremos m clases y un conjunto N de patrones de muestra , cuya clasificación es conocida a priori. Sea x un patrón arbitrario entrante, el enfoque de Nearest Neighbor (“vecino más cercano”) asigna a x a la clase donde el patrón se encuentra más cerca del conjunto , es decir, si
(6)
entonces . Este esquema es básicamente otro tipo de clasificación por mínima distancia, se puede modificar mediante la consideración de los k vecinos más cercanos a x y el uso de un clasificador tipo regla-mayoritaria.6
2.5.2 Naïve Bayes
Consideremos un número finito de clases {C1,C2,…,Cm} y un vector característico x en Rn. Cada componente de este vector es una característica escalar significativa de Ci,1 ≤ i ≤m. El vector característico es una variable aleatoria dada una distribución de probabilidad condicional p (x | C i ),1 ≤ i ≤ m. Si denotamos a p ( x | C i ) como la probabilidad a priori que tiene un patrón entrante de pertenecer a una clase C i, entonces la probabilidad a posteriori de este patrón con un vector característico adjunto x para pertenecer a C i, está dada por la siguiente fórmula de Bayes:7
(7)
donde
(8)
es la probabilidad de distribución de x
2.6 Matriz de confusión y porcentaje de exactitud
En los algoritmos de reconocimiento de patrones, la matriz de confusión es una herramienta de visualización que se emplea en aprendizaje supervisado. Cada columna de la matriz representa el número de predicciones de cada clase, mientras que cada fila representa a las instancias en la clase real. Uno de los beneficios de las matrices de confusión es que facilitan ver si el sistema está confundiendo dos o más clases. La Tabla 1 muestra un ejemplo de matriz de confusión.
Clase verdadera
C1
C2
C3
Clase predicha
C1
VC1
FC2
FC3
C2
FC1
VC2
FC3
C3
FC1
FC2
VC3
Tabla 1. Matriz de confusión
En donde Cn representan las clases a clasificar, VCn representan las clases verdaderas que son correctamente clasificadas y FCnclases falsas que no son correctamente clasificadas.
La exactitud (Exc), es la proporción del número total de predicciones que fueron correctas divididas por el total de muestras (Tm) y multiplicadas por 100 Se determina mediante la siguiente ecuación8:
(9)
2.7 Validación cruzada
En la validación cruzada k-fold (también llamada estimación de rotación) la base de datos D es dividida aleatoriamente en K subconjuntos exclusivos (las particiones) D1,D2,… Dk aproximadamente del mismo tamaño. El inductor es entrenado y probado K veces; cada vez t ∈ {1, 2, …, K}, es entrenado sobre D \ Dt y probado sobre Dt . La validación cruzada estima la exactitud del número total de clasificaciones correctas, dividido por el número de instancias en la base de datos. Formalmente, D(i) es el conjunto de pruebas que incluye instancias xi = vi ,yi , entonces la validación cruzada estima la exactitud:
(10)
La validación cruzada estimada es un número aleatorio que depende de la división en las particiones. La validación cruzada completa 9 es el promedio de todas las posibilidades para seleccionar m/K instancias de m.
3. Desarrollo
A continuación se enunciarán los pasos utilizados durante el desarrollo de este trabajo, en donde básicamente se siguieron las etapas del proceso de reconocimiento.
3.1 Captura
El primer paso consistió en la captura de audio, esta se realizó con un micrófono AKG Perception 220 conectado a una interfaz Profire 2626 m-audio y esta a su vez a una computadora con un software de captura y edición de audio. Se realizaron 120 capturas diferentes divididas en tres clases o tipos de sonidos.
Las clases son: Voz, tambores y platillos.
Muestras
Clase 1
Clase 2
Clase 3
Tipos de voz
Tipos de tambores
Tipos de platillos
Hombre
Tom 12”
Hi-hats 14”
Mujer
Tom 13”
Crash 16”
Tom 16”
Crash 18”
Tarola
Ride 20”
Bombo
Splash 12”
Tabla 2. Muestras de audio capturadas.
Una vez capturadas las 120 muestras de audio, se procedió a obtener las imágenes del espectro de frecuencias de las mismas. Éstas se obtuvieron utilizando el mismo software de captura. Al final, se tienen 120 imágenes, 40 para cada clase de objetos.
3.2 Tratamiento y segmentación
Como las imágenes por su naturaleza son de fondo negro y la gráfica del espectro de frecuencias con varias intensidades de color (rojo, naranja y púrpura), no se requirió un tratamiento de las imágenes, así mismo, la segmentación de una imagen consiste en invertir la misma y convertirla a escala de grises. A continuación se muestran las imágenes que describen el proceso:
a)
b)
c)
Fig 3. Imágenes correspondientes al proceso de segmentación, a) imagen original, b) imagen invertida, c) imagen en escala de grises.
3.3 Caracterización
Una vez segmentadas las 120 imágenes, se prosiguió a realizar el cálculo de los descriptores de la imagen, en este caso, el vector de características (Vc ) para cada imagen queda conformado por los descriptores mencionados en los conceptos teóricos y se ordenan de la siguiente manera:
(11)
donde es la mediana, σ² es la varianza. E es la energía y e es la entropía.
Una vez caracterizadas las 120 imágenes, se almacenaron cada uno de los vectores de características (cada uno de dimensión R⁴) en una base de datos llamada “ImageData”, la cual consta de 120 tuplas y 4 atributos (120X4). Cabe señalar que la base de datos está diseñada de la misma manera que las bases de datos Iris Plant y Wine, ambas pertenecientes al repositorio “UCI Machine Learning Repository”, las cuales son bases de datos diseñadas para probar algoritmos de reconocimiento de patrones, ambas utilizadas en gran parte del estado del arte; estas cuentan con 150 tuplas y 4 atributos. Así mismo, el diseño de la base de datos se realizó de esta manera ya que lo que se pretende con este trabajo es probar la hipótesis inicial, la del reconocimiento de sonidos mediante imágenes.
3.4 Proceso de clasificación
Por último, se realizó la clasificación de los patrones (incluidos en la base de datos) utilizando los algoritmos de clasificación supervisada K-Nearest Neighbor (con un valor de k=1) y Naïve Bayes. Así mismo, con la finalidad de verificar la integridad de la base de datos y el desempeño de cada uno de los algoritmos, se utilizó la validación cruzada 10, en donde se realizaron 10 particiones (K-folds) para la selección de las muestras para su entrenamiento y recuperación. Las pruebas de clasificación se realizaron para la base de datos ImageData.
4. Resultados
A continuación se muestran las tablas con los resultados obtenidos, utilizando la validación cruzada, en estas se muestra cada partición (K-fold) correspondiente y su porcentaje de exactitud asociado:
K-Nearest Neighbor
Naïve Bayes
1
88.2
1
89.7
2
85.1
2
92.3
3
85.1
3
92.3
4
84.3
4
92.3
5
88.3
5
91.0
6
85.2
6
92.3
7
88.2
7
93.5
8
91.0
8
92.3
9
87.1
9
93.5
10
91.0
10
91.0
Exactitud promedio
87.35
Exactitud promedio
92.05
Tabla 3. Resultados de exactitud para KNN
Tabla 4. Resultados de exactitud para NB
Conclusiones
Con el desarrollo de este trabajo se verificó la hipótesis inicial, en donde se concluye que es posible clasificar sonidos a través del análisis de la imagen del espectro de frecuencias tomando como descriptores la media, varianza, energía y entropía. También, se pueden enumerar las siguientes conclusiones, de acuerdo al análisis de los resultados.
1. Los descriptores propuestos para generar el vector de características, cuya tarea fue la de caracterizar cada una de las imágenes del espectro de frecuencias del sonido, resultaron adecuados para realizar los procesos de clasificación, sin embargo, se debe profundizar más en el comportamiento de los mismos, para identificar posibles correlaciones.
2. A través de la validación cruzada se concluye que, para este trabajo, bajo las condiciones establecidas (tratamiento, segmentación y caracterización), el algoritmo de mejor desempeño fue Naïve Bayes, ofreciendo un porcentaje de clasificación promedio del 92.05% en las pruebas realizadas.
Como trabajo futuro, se propone explorar con otras técnicas para segmentar las imágenes, así como el uso de diferentes descriptores para caracterizar las mismas, además es recomendable aumentar la población de vectores característicos y el número de clases, con la finalidad de lograr mejorar los resultados presentados en este artículo y robustecer el método.
Referencias
1. SCHIFFMAN, Harvey. La Percepción Sensorial. (2001). Limusa Wiley. p. 72. ISBN 968-18-5307-5.
2. BAUGHMAN RP, Sound spectral analysis of voice-transmitted sound, Loudon RG, The American Review of Respiratory Disease [1986, 134(1):167-169].
3. GONZÁLEZ, Rafael C. and WOODS, Richard E. Digital image processing. Prentice Hall, New Jersey, 2 edition, 2002b. pp. 25-30.
4.
GONZÁLEZ, Rafael C. and WOODS, Richard E, op cit, p. 88.
5. CALZADA, Valentín y ORNELAS, Manuel. Análisis de componentes principales aplicados al reconocimiento de objetos 3D bajo rotación, Research in computing science, Vol. 62, pp. 197-206, ISSN: 1870-4069.
6. FRIEDMAN, MENAHEM, KANDEL and ABRAHAM. Introduction to pattern recognition: statistical, structural, neural, and fuzzy logic approaches. Volume 32 of Series in machine perception and artificial intelligence. Singapore River Edge, N.J. World Scientific, 1999. ISBN 981-023312-4. p. 65, p. 106.
7. FRIEDMAN et al, op cit.
8. FAWCETT, Tom. An introduction to ROC analysis. Pattern Recognition Letters, 27:861–874, 2006.
9. KOHAVI, Ron. A study of cross-validation and bootstrap for accuracy estimation and model selection. International joint conference on artificial intelligence (IJCAI), 1995.
10. KOHAVI, Ron, op cit.
Universidad Tecnológica de León. Todos los Derechos Reservados 2013

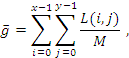 (2)
(2)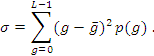 (3)
(3)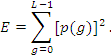 (4)
(4)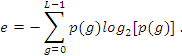 (5)
(5)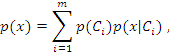 (8)
(8)